JDSC 製造業チームのデータサイエンスディレクターをしています、森浩太です。私の思う製造データサイエンスのこれまでとこれからについて紹介します。

森 浩太
CONTENT
自己紹介にかえて
自己紹介にかえて、自分の人生に最も影響を与えたものについて書きます。ひとつ挙げるなら、それはYale大学留学時代に受けた統計学部のJay Emerson教授の講義です。確か2009年だったと記憶しています。当時、経済学部の博士課程に在籍していたのですが、隣りにある同じ学部の友人に誘われて受講しました。「Case Studies」という抽象的なタイトルの講義で、この前後でものの好みも取組内容も大きく変わった、自分にとってのターニングポイントでした。

Yale University, Hillhouse Avenue. ※1
「Case Studies」の授業では、大学の所在するNew Havenという街の不動産情報を集めていました。分析するのではなく、集めるところからやるところがめずらしい。不動産情報サイトの物件情報を機械的に読み込んで、間取りやサイズ、カテゴリなどの情報を抽出し、名寄せをして表記揺れなどを解消して、最終的に使えるデータにしていく、というものです。今となっては割と普通のことで、人によっては「あぁ、ウェブスクレイピングね」と思うかもしれないですが、当時の自分には衝撃でした。それ以降、この技術を使ってオリジナルのデータセットを作ることと、それを使って独自の分析をするということに没頭するようになりました。
ちなみに、教授にクラスの単位取得のために何をすればよいか相談したら、彼も僕がスクレイピングが気に入ったことを理解していたのか、何か一つデータを作れと言われました。なので、アメフトの選手や試合結果のデータを集めて提出して単位をもらいました。博士論文では、日本の新聞社説のデータをできる限り大量に集めて自然言語処理と市場分析を行ったので、もろにこの講義の影響を受けています。
スクレイピングの他にも大事なことを教わりました。その講義の中盤に課題が出されました。採用活動の記録を集めたデータが渡されて、これを使って判断が人種差別的であるかを評価せよ、というものでした。自分も含めて皆それぞれ学んできた統計モデルを当てはめて色々と考察をしました。確か自分はロジスティック回帰をして人種変数の係数を評価するようなことを行ったと記憶しています。結果は(おそらくほぼ)全員が不合格。解説で、教授はいくつかのデータの可視化を見せて、「こうするとデータの偏りと不完全性がわかるだろう。したがって、このデータから導かれるいかなる結論も無意味だ」というわけです。初見殺しというか通過儀礼的な宿題だったのかもしれません。その日の授業のパンチラインは、今でも覚えています。 “Lessons learned. Your data stink.” これは今でも僕の座右の銘です。

Prof. Jay Emerson. “Your data stink.” ※2
※2 画像引用元 https://statistics.yale.edu/people/jay-emerson
仕事を始めて運良くデータサイエンスを生業にしてからも、やっていることはさほど変わっていません。プログラムを動かす場所がパソコンからクラウドサーバーになったり、テキストファイルがSQLのデータベースになったりはしましたが、本質は変わらず、良いデータを集めることとそれを丁寧に分析することが仕事です。
製造業・金型・データサイエンス
製造業に触れるようになりよく思うのが、自分はつくづくソフトウェア上の技術で生きているということです。データを整理するのも解析するのもソフトウェアで完結する仕事です。データサイエンスやコンピュータサイエンスにも、サーバーの物理構成やGPUチップの構造みたいにハードウェアに関わる分野もあるはずですが、そこは自分の通ってきていない道です。一方で、ものづくりでは物理的なモノが主役で、ハード的な要素が必ずついてきます。そこが自分のようなタイプには難しく、面白くもあります。
身の回りの工業製品の部品の大部分は、金型で製造されています。たとえばプラスチック製品だと製品形状の金型を用意し、そこへ溶かした材料を充填し冷却して固めるというように作るのが代表的です(射出成形)。金属の部品の場合は、板状の金属材料を金型の間に配置して、プレス機で上下から挟むなどの加工方法があります(プレス成形)。
https://en.wikipedia.org/wiki/Stamping_(metalworking)
こうした金型を用いた製造では、短時間に大量の製品を作ることができます。他の方法として、工作機械を用いて材料を削るなどの機械加工や、あるいは3Dプリンターを使っても同じものを作れるかもしれませんが、それだと時間がかかってしまうそうです。大量生産のためには金型が良い、とのことです。
金型の前には製品設計があります。作りたい製品の設計図があって、それを作るための金型を設計し、金型を作成するというのが通常の流れです(なお、金型は大量には作らないので、工作機械で作るのが一般的だそう)。製品の設計図は、CADソフトなどで作られた、2次元もしくは3次元の図面です。ここで漸くデータらしきものがでてきました。
2次元図面であれば、画像です。よくあるピクセルごとの色を定めて画像を表現することもありますが、図面の表現を正確に行うならば、ベクトル化したもの、つまり線分や円弧などの集合として画像を定義したものの方が良い場合があります。ピクセル状の画像ファイルの形式にはJPGやPNG、ベクトル画像の形式にはSVGなどがあります。CADソフトウェアとの変換では後者の方が相性が良いです。

SVGファイルの例
3次元の図面は専用の商用ツールで作られることが多く、ツールごとに異なる規格が存在します。データの表現形式も種類があって、代表的なものに、ボクセル方式(3次元空間を等間隔に区切り、各グリッドが値を持つ形式)、メッシュ方式(3次元形状を多角形の集合で表現したもの)、点群方式(形状の表面または内部の点の集合で表現したもの)などがあります。分析者視点で比較的使いやすいものにはSTL形式があって、これは三角形の集合によって形状を表すメッシュ方式のファイル形式です。機械学習目的では点群データがよく用いられ、特に PointNet, PointNet++ などの深層学習機構が、点群入力データの分類で結果を残してきています。

引用元 Example of a STL file format and its model
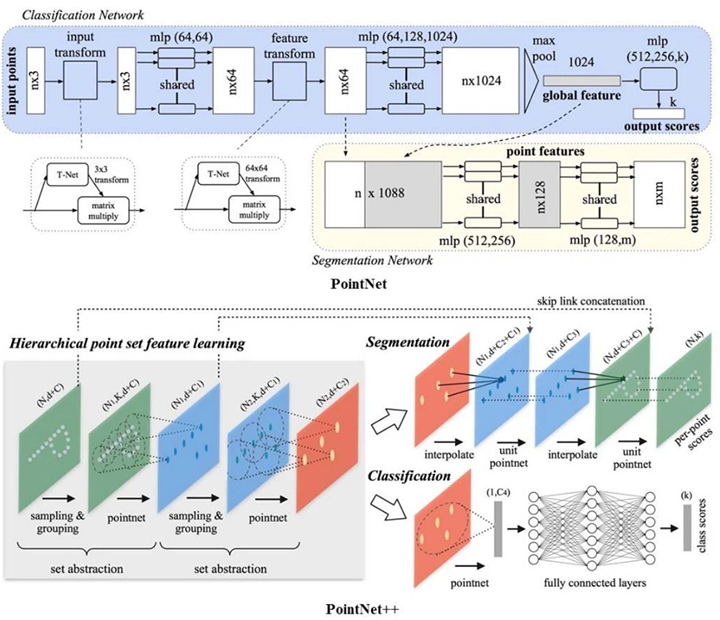
PointNet: Charles et al. (2017), PointNet++: Qi et al. (2017)
製品図面のCADファイルをデータとして捉えると、様々な応用先が考えられます。ひとつは、それを成形するための金型の特性を推測するということです。たとえば、同じ機能の製品でも、金型にしやすい形状とそうでない形状があります(射出成形では製品が金型から抜けないなど)。その困難さをアルゴリズムで評価できるなら、金型設計に入る前に非現実的な製品設計を避けることができます。金型の部品の点数や開発コストなども特性の一種とみなして予測する対象になりえます。その他にも、穴の個数やサイズ、曲げ回数など製品図面の中から自動検知したい有用な情報があります。あるいは、CADファイル間の類似性を評価することで、過去の似た製品とその金型設計を参照する、ということも考えられます。こうした仕組みは、後工程である金型の設計や作成を意識した製品設計を支援することができる可能性があると考えられます。実際にこうした取組みが動き始めており、今後の展開を非常に楽しみにしています。
製造データサイエンスのこれから
ここまで書いてみて思うのですが、やはりソフトウェア思考が残るようです。ものづくりのことを考えていたら、設計図はCADファイルでデータになる、となって、それを統計的に分析することを考えている。ものづくりをデータ分析側へ寄せる思考になりがちです。必ずしも悪いことではないと思うのですが、これはある意味で「ハンマーを持つと全てが釘に見える」症状とも言えそうです。
個人的には製造データサイエンスはもう少し柔軟で良いと思っています。データサイエンスをものづくりに寄せる、つまりは、実際にモノを作るということです(もちろんデータを使って)。具体的にどうやるかはまだ秘密ですが、これは2025年の裏テーマです。ご期待ください。
今回は製造業テーマの中でも設計図面と金型にフォーカスしましたが、他にもチャレンジはいろいろあります。工場内の生産計画やそれに基づく生産工程の差配、工場内外の物流、製造機械のメンテナンスなど、あらゆる場面で生じるデータに可能性がまだ眠っています。機会に恵まれたら、近いうちにまた書こうと思います。これもご期待ください。


{kind=link}